Poppycock and Jabberwocky: The Impending Collapse of Free Range Language Models and Just About Everything Else
Authenticity.
Its value is almost inestimable. Politicians crave it. Business leaders dedicate endless hours to secure it. Every pretender to the public’s attention, clergy, street poets and TikTok influencers, hopes to possess it even while crafting prevarications that belie their very intent. That which is authentic is without posture or ulterior motive. It does not seek to manipulate or influence. It is the foundation of trust upon which all other transactions rely and without which nothing of substance proceeds. Contracts, treaties, agreements even marriages can’t be consummated without the understanding that the parties are representing their motivation, character, commitment, assets and intent authentically. Some even require that you attest to such in writing, pledging no less than your life, fortune and sacred honor. Authenticity is at the root of humility, it does not boast or brag, it has no need to, what you see is what you get.
In technology circles these factors have been accepted for years, in fact, several very large categories of tech concepts, products and services are predicated on this very notion. Blockchain, IAM, Cryptography and Security all have authentication as a primary part of their value proposition. Conventionally, to access trusted computing resources one must provide appropriate credentials, one must “authenticate” who they are. These days even simple passwords aren’t enough. Tinder just announced that to remain a member you had to provide not only a picture of yourself but a video holding up a newspaper with a visible date and current headline. Kind of a “Stockholm Survivor” authentication. Next they’ll have you send in an ear and a self portrait looking like Van Gogh.
Corporations sometimes require multi-factor authentication of both you and the equipment you might be using. If the machine ID and the IP address aren’t immediately familiar, you might not be granted access. The same may be true for resources buried deep within a computational facility such as containers in a shared cloud facility. Credit services match your expected location to transactions and will alert you if they suspect them to be less than congruous. In China you might be required to submit to facial recognition before gaining access to a public bathroom and toilet paper. The list is long. But recently we have seen the concern for authentication move from the world of people and things to the world of images, concepts and data.
And this is where our story begins.
Over the past few months we have seen a storm brewing between established content publishers and AI model providers, the former seeking to enforce copyright privileges and the latter looking to train their models on as many acceptable parameters -think of them as tokens, vectorized thingamabobs- as they can possibly lay their hands on. Nothing out of the ordinary here, just a competition of opposing interests. But what this tussle has brought into stark relief is the authentication of data and the role that might play in the use of AI models, particularly free-range models.
So what’s a free-range AI model?
Well, exactly what the name implies. Generally, it is open sourced, open weighted and insatiably omnivorous, consuming all manner of content regardless of pedigree or provenance. These models are often free to download and come preloaded or trained on various approved and sanitized corpora. But as the name and licensure imply, anybody who is inclined can tinker with the training as well as set their own prejudices and predispositions when it comes to creating prompt based replies. They are also free and sometimes even required to share any changes with any other party seeking to use the same model.
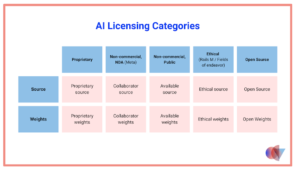
Source: “AI Weights Are Not Open Source”, by Sid Sijbradij courtesy of Open Core Ventures
This is exactly how Google’s Gemini came up with a “no whites need apply” pictorial rendering of historical references and what some claim were renegade Copilot versions of Taylor Swift’s unclad likeness. It’s bad enough when home made language models experience dot-product attention induced hallucination but quite another when it burps out psychotic conjecture predicated on woked-out tuning and adolescent sexual fantasies. But once a large language model (LLM) goes rogue, once its content becomes the input to other models relentlessly scouring the internet for passable tokens, authenticity becomes a mere smudge, just another dead bug on the windshield of some mindless internet screen scrapper.
However, when it comes to technology, an enduring article of faith is that what some technology can screw-up, more technology can put right. This has been the relentless mantra of nearly every Microsoft security patch ever issued. But when it comes to LLM’s things might not be so simple. It’s becoming abundantly clear that the value of these models rests on the disciplined curation of the data they consume. Sound familiar? Garbage in, garbage out? But what may also seem familiar is that nearly every successful internet business platform relies on very specific curation of data. These same players are contributing their open source/open-weighed, customizable models to the broader tech community, along with a host of other contenders, with little if any auditing or validation of construction. But instead of relying on a hand full of monopolistic internet players, thanks to open source, open weighed models, we seem to be be headed to an era where every pretender to the public’s attention will have their very own bespoke LLM producing their very own bespoke version of reality; kinda like Stanley Kubrick and Hunter S. Thompson dropping acid in a bouncy house.
I know absolutely nothing and I’m prepared to prove it.
Naturally, these circumstances have garnered quite a bit of attention. Over the past few months start-ups and industry consortia have formed to promote the adoption of AI specific content authentication methods, models and solutions. Some of these involve verifiable attestation of authorship. Some involve the embedding of “watermarks” to clearly call out the source of AI created content. For instance, metadata can be incorporated into images and text that would clearly identify the authorship behind published content. There are a number of techniques that can be employed including the manipulation of data at the pixel, character, word, format, page or corpus level that would be detectable at both large and small scales such that even very small fragments of data would be identifiable. The only problem with these techniques is that most of them are easily scrubbed and removed for a host of valid reasons, some legal and some technical. The legal issues usually boil down to inadvertent attribution or lack there of which takes us back to the copyright issues mentioned above. The technical issues pertain mostly to the amount of overhead needed to compress, store, transmit, and manipulate huge volumes of ubiquitous metadata. As a rule, most of the internet players promoting AI platforms simply dispense with this headache by removing all content metadata before pushing user generated content to their own internet platforms, a technique that for practical reasons, they are likely to employ when training their publicly available LLM’s.
So, in what seems like a future inevitability, blockchain has once again emerged as a logical contender for the data authenticity – data attestation issue (see Lies, Damn Lies and Statistics – May 2023). It would be relatively straight forward to have models accessing public data to simply sign in and provide evidence of their subscription via blockchain protocols but, thanks to copyright issues, it isn’t likely and besides without a preponderance of subscribers the attestation is mostly meaningless. And this doesn’t even begin to address what will be the larger issue of models sourcing training data from the largest global pool of inauthentic crap that ever existed, the internet.
Recently, another technique emerging from the blockchain community has been nominated as a candidate to aid in the authenticity conundrum, zero knowledge proofs, more specifically Zero-Knowledge Succinct Non-interactive Argument of Knowledge or zk-SNARKs. As currently proposed, the specific knowledge of a model’s construction and layered attention mechanisms would be used to determine whether or not the manner in which it processed a query could be used to validate the provenance of the model and thereby, by inference, possibly suggesting the origin of the data. This is a highly indirect approach and one facing a pretty steep horizon of diminishing returns but it might prove to be the only game in town (see Beyond the Cyber-Cryptoverse – February 2019).
The implication being that for the thousands or possibly millions of free range LLM’s spewing content back out to the internet there will be no practical way to authenticate the source of their own content and this has the potential to become the beginnings of a system wide model collapse, given that models with legitimate pedigrees are already scouring the internet for input.
Do you smell something?
Common sense would dictate that breathing your own exhaust may eventually prove toxic, even fatal (see The Paltry Cost of Priceless Externalities – January 2020), breathing someone else’s exhaust can turn you into teenager with a social media addiction, which is why more and more enterprises are building and maintaining their own LLM’s. So here we have a scenario where every model becomes its own proprietary content publisher even if they all pretty much publish the exact same indistinguishable gunk sourced from that global pool of crap called the internet. The only way around this is to maintain tightly controlled and curated proprietary models that only ingest pristine, authenticated data. Walled gardens. In other words, things are about to get a whole lot more expensive for any enterprise that hopes to extract marginal value from employing a proprietary large language model.
Meanwhile, free range models and proprietary walled gardens will both eventually succumb to model collapse largely due to their data acquisition strategies; the former due to dilution of relevant dot-product signals from internet soaked attention mechanisms turning their output into a puddle of undifferentiated mush, the latter due to a well known a side effect of tightly curated statistical distortion. As we noted in Innovation: Power Laws and the Adjacent Possible – March 2017, Poly Urn models show that the selection and promotion of a single member or token of a given cohort will increase the probability of that member being continuously selected in what’s known as a “winner take all” phenomenon. In Large Language Models, if the population of tokens isn’t constantly refreshed and increased it will eventually select and promote the same tokens based on existing attention mechanisms which will result in undifferentiated responses to different prompts, aka model collapse or just another, albeit different, kind of mush.
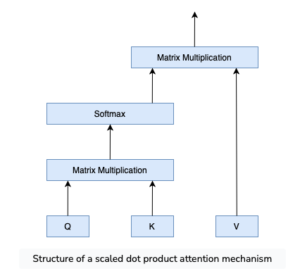
Source: “What is the Intuition Behind The Dot Product Attention”, courtesy of Educative
The promise of today’s generative AI is that it will expand the horizons of knowledge utilization across a limitless number of human endeavors. A large and somewhat preposterous ask given that LLM’s don’t operate on or recognize “meaning”, that’s something that only happens when a human reads their output and deciphers it as a string of cogent, intelligible symbols. LLM’s construct content spun from vectorizable thingamabobs signaling and seeking statistically reinforced connection, aka highly sophisticated auto-complete bots. It happens to feel familiar because people rely on similar but more organic phenomenon to establish meaningful representation. According to schools such as Constructivism, collective meaning is like a giant thought bubble being tossed about at an AC/DC concert like a giant beach ball, every bounce and bat is an evolutionary causing contribution, every roar of applause and squeal of feedback registers and is incorporated into a collective model of inchoate meaning. The mob, the moment and the music give the thought bubble its meaning; without them its just another lonely beach ball leaking air, kinda like your average free range LLM. (see AI: “What’s reality but a collective hunch?” – November 2017)
What LLM’s also don’t possess is the capacity to imagine conceptual adjacencies or something even more practical the ability to construct useful analogies and cohesive metaphors (see Innovation and Analogy – August 2017). Both of these figure prominently in the calculus of language and in defining the “essence” of a concept or phenomenon. Imagination is what we employ to see beyond the familiar when we reach the frontier of existing knowledge and all of these abilities are at the root of creating testable counterfactuals and extensions to existing human knowledge (see Stalking the Snark – May 2019). And while LLM’s are useful in detecting and projecting patterns, since they are incapable of recognizing meaning, they really aren’t adept at imagining new possibilities from existing knowledge.
The more money and effort that gets poured into LLM’s the more likely it is that our expectation for their utility becomes tempered. This will not happen overnight. Billions more need to be shoveled into the gaping maw of techno-hype before more reasonable expectations emerge. In the meantime, we are about to enter the Age of Jabberwocky where gyre and gimble are all the rage and will all public passions sway but once we come galumphing back, we’ll find that poppycock fills our sack and hardy much of any thing more.
You remember poppycock, from the old Dutch: pappe meaning “soft” and kak meaning “shit”.
Put that in your thought bubble and watch what happens.
Cover image, fragment of The Jabberwock, illustration from the original publication by John Tenniel, 1871 courtesy of Wikipedia. All other images, statistics, illustrations and citations, etc. derived and included under fair use/royalty free provisions.
